Renowned Edge AI technology company, DeGirum Inc., has just taken a significant step forward in the open-source community by making public a new GStreamer plugin repository on GitHub. The repository, accessible at https://github.com/DeGirum/dg_gstreamer_plugin, was made public on May 17, 2023, and has since sparked widespread interest in the technology sphere.
The GStreamer plugin is designed specifically to add support for DeGirum proprietary hardware, the cutting-edge AI accelerator known as Orca. GStreamer, a robust, open-source multimedia framework, allows developers to create a variety of media-handling components. DeGirums contribution to this versatile ecosystem aims to enhance the functionality of GStreamer-based applications that leverage their Orca technology.
The Orca Edge AI accelerator is a significant innovation in the field of artificial intelligence, enabling high-speed processing and real-time analytics at the edge of the network, reducing the need for cloud-based computations. This GStreamer plugin is expected to improve the ease and efficiency of integrating Orca into multimedia projects.
DeGirum release of this repository aligns with the spirit of open-source development, promoting collaboration and knowledge sharing. - We are excited to share our new GStreamer plugin with the world, - said a spokesperson from DeGirum. - By making this public, we hope to foster collaboration and innovation in Edge AI applications, whilst making our Orca technology more accessible.
Developers and tech enthusiasts worldwide are eagerly exploring DeGirums code, with early feedback being overwhelmingly positive. By making the plugin available to the public, DeGirum encourages developers to contribute to its evolution, enabling them to adapt and customize the plugin to suit their project needs.
This new plugin not only consolidates GStreamers position as a pivotal tool in multimedia development but also underscores the growing significance of Edge AI technology. It highlights the ongoing importance of open-source development, where transparency and collaboration continue to fuel innovation.
As the tech community delves into the features of DeGirums GStreamer plugin and its support for the Orca AI accelerator, the future of open-source multimedia development seems brighter than ever. The role of companies like DeGirum, in this landscape, is paramount as they continue to contribute to an ever-evolving ecosystem.
Background
The past few years have seen an explosion in the number of semiconductor companies developing custom AI HW accelerators, especially for applications at the edge. Each new offering claims unprecedented performance, efficiency, and ease of use. One would expect that such a competitive landscape gives application developers a wide range of options to bring their applications to life. While there is increasing adoption of AI at the edge, the pace at which this is happening is rather slow. What can explain this phenomenon?
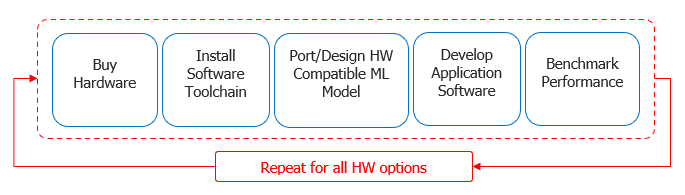
A Catch22 Situation
Application developers today face a fundamental dilemma:
- Should they develop their AI applications first and then choose the HW to deploy these applications OR
- Should they choose the HW first and then develop their applications for the HW?
A development first approach does not work because the SW tools to develop applications are specific to the HW.
Even the machine learning (ML) models and tools for porting the models can be HW dependent, as not all models are compatible with all HW options. At the same time, developers cannot choose the HW first because it is almost impossible to determine if a particular HW can provide the required performance without developing the application SW. This is because the performance specifications provided in the datasheet do not translate to real application performance. Hence, edge AI application developers today are caught in this Catch22 situation: to develop their application, they need to choose a HW option and to choose a HW option they need to develop their application. This dilemma has forced the developers to adopt the following workflow for their development.The result of a such a workflow is that the developers end up with multiple software stacks and models, one for each HW, leading to a lot of wasted time, money, and effort.
Choosing HW is Difficult
A wide range of applications can benefit from deploying AI at the edge. Consequently, the compute requirements for these applications are quite different, which means that there cannot be a single HW that is suitable for all use cases. The advent of custom AI HW accelerators targeting various applications has led to a very crowded market where everyone is trying to differentiate themselves from other similar offerings. Unfortunately, comparing two HW options is not an easy task. Device specifications as well as benchmark reports fail to provide a fair way to compare different HW offerings.
The primary reason for this difficulty is the fact that there too many metrics to measure performance with no standard way of measuring those metrics. HW vendors advertise metrics such as TOPS, TOPS/Watt, FPS, FPS/Watt, FPS/$, and so on. Each vendor has their own way of measuring these metrics.
For example, let us consider two HW options, say HW A and HW B. If the specifications say that HW A has X TOPS and HW B has 2X TOPS, it does not necessarily mean that HW B will have 2x the performance of HW A. This is because different HW options can have different efficiency in using these TOPS.
Similarly, each vendor may have a different interpretation of what TOPS/Watt means. Some consider only the matrix multiply unit and ignore other parts of the accelerator, while others consider the total module power (such as USB module or M.2 module).
When it comes to metrics such as FPS, FPS/Watt, and FPS/$, we encounter similar issues. HW vendors typically quote FPS numbers for some models such as ResNet50. While such a number may give a general idea of the capabilities of the HW, it cannot be used to estimate the performance of other models.
More importantly, benchmarks do not capture other important aspects of HW such as flexibility. Since the new generation of accelerators are optimized for specific use cases, they typically sacrifice flexibility to achieve higher performance and efficiency. The HW can be limited in terms of the models they can run (vision/speech/text), the precision of the models (FP32/FP16/INT8), the number of models that can run at a time, and the size of the models they can run. It is a tall order to capture all the limitations of the HW in the datasheet and even more challenging to understand what the implications of those limitations are for a particular use case.
DeLight Cloud Platform
As we started engaging with customers, we found out that the main problem faced by developers is as follows: How to evaluate a given AI HW and compare it against others in a short amount of time?
The DeLight cloud platform was built to solve this pain point. Specifically, we wanted to provide all our prospective customers a quick way to verify the claims we make about our HW and SW. Since evaluating HW and developing SW for a custom HW is a long process, we investigated ways to make this process as simple as possible. As a result, we developed our python software development kit (PySDK) in a way that allows users to work with our HW located in the cloud. This means that developers can start working on applications without having to go through any HW setup and by using a simple python package.
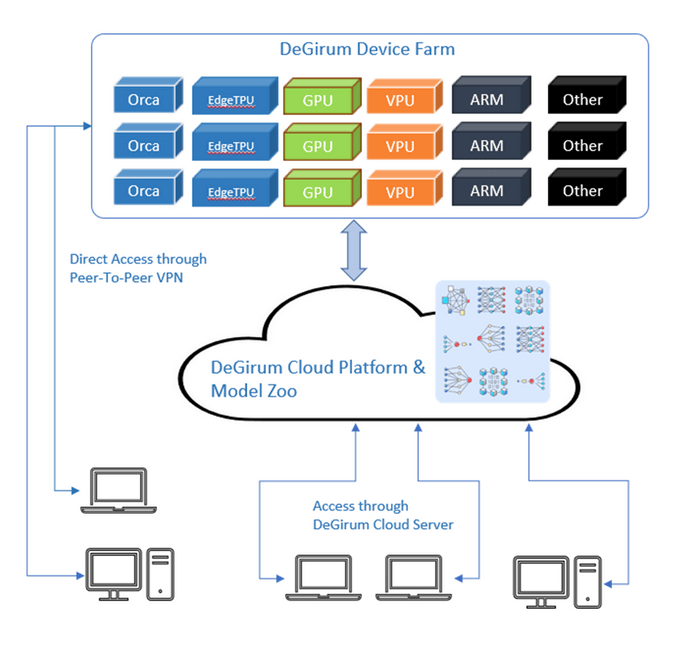
The DeLight cloud platform accelerates application development with the following features:
- Cloud access to HW: This reduces upfront investment on HW and allows developers to start with application development in a matter of minutes.
- HW agnostic APIs: These ensure that a single SW stack can be developed for all HW options.
- Cloud tools for model porting: The cloud platform not only provides a rich model zoo of ready-to-use ML models but also provides tools that allow users to bring their own models.
Once the applications are developed using the cloud platform, the various HW options can be evaluated and the best option can be chose for deployment. The PySDK is designed to allow the developers to use the same code for deployment as well. Once the applications are deployed at the edge, the cloud platform also provides tools that simplify ML model management and deployed device management. The cloud platform allows users to provision cloud zoos that all the deployed devices can connect to and download the ML models from, thereby greatly simplifying model management. The platform also provides a dashboard to monitor the health of all the deployed devices.
Future of the Platform
The cloud platform is a central part of DeGirum's strategy to simplify the development and deployment of sophisticated AI applications at the edge. We are actively engaged with our customers to gather their feedback and enhance the capabilities of the platform to accelerate the adoption of AI at the edge.



